LipZip c++ Node P1
LipZip: Lets be honest, we really don’t have anything that resembles a nice clean solution in Maya do we? Instead there’s a lot of `creative’ workarounds floating around out there to solve what is essentially blending transforms from one place to another.
And that’s all this really should be; a transform exercise[after the fact].
Do you really want some arduous toil of creating curves [for every characters lip region], subsequent duplication of these to create blendshapes / ribbons / massive networks of shadingNodes[setRanges etc] for value remapping / wires / create benign cycles etc in your rig just to move a transform from one location to the other! It’s a hell of a lot of overhead to have in a rig in my opinion that could be better spent else where.
So two people who spring to mind would be Chad Vernon and Stephen Candell. Chad’s approach is from a deformer standpoint whereas Stephen’s is from a matrix Zipping point of view. Both entirely valid, (though the deformer would fall down more in game rigs until such support enters the realm of those engines).
To that end I’d go out on a limb and say both Chad’s and Stephens networks look similar to each other (maybe Chad’s is probably somewhat smaller as it’s a deformer?) in so far a node complexity.
Here’s a look at the network in Stephen’s video;

Against something like;

I know which I’d prefer to handle, and I know which one I’d prefer to make scripts for.
When it comes to posts about C++ nodes, we get a few videos of their nodes, with little to no insight as to how it’s done. I’ve decided to have a stab at Stephens approach to see if it might stimulate you to take a dive at your own [less convoluted] solution too!
Here are the results of the node I’ve mashed together as a proof of concept to avoid all the blendshapes / curves and subsequent ribbons and follicles etc etc;
You may think they’re easier, but I beg to differ. You’re prob creating all kinds of scripts to handle these setups, and layering in all kinds of unnecessary nodes/surfaces/follicles etc that could otherwise be avoided… and result in a rig that runs faster as a result!
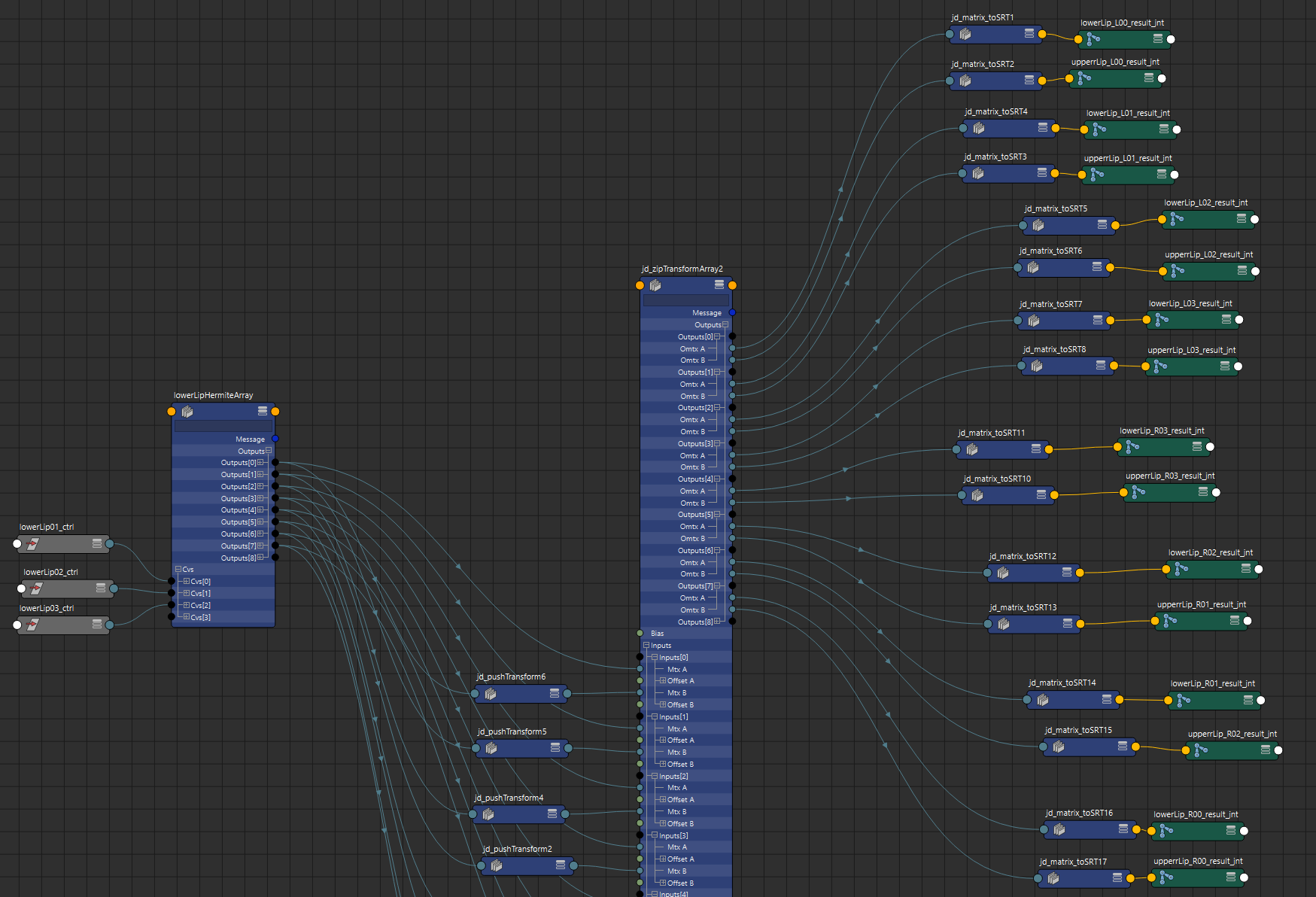
This takes Stephen’s idea and dumbs it down a bit. I’m not trying to create a curve inside the node etc. I’m literally taking 2 inputs, and outputting 2 outputs. eg: upperlip01 and lowerlip01 pairs blending these inputs to a mid point based on the zip 0-1 input value.
The result?

In this setup the Zip is the LAST part of the chain. The lips follow the jaw, etc etc. Then after all that is done calculating we can take the positions of the top and bottom lips and create the lipZip effect from those locations.
We can bias the effect between the upper and lower lip positions, (as seen in the first part of the gif) and we can change the direction L-R R-L L->M<-R as we treat the 0-1 zip attribute as time along a `curve’.
So that’s it for my first rant.. More later re the code for my approach to this. And hopefully that motivates you to avoid some convoluted and quite frankly unnecessary workarounds as well.